
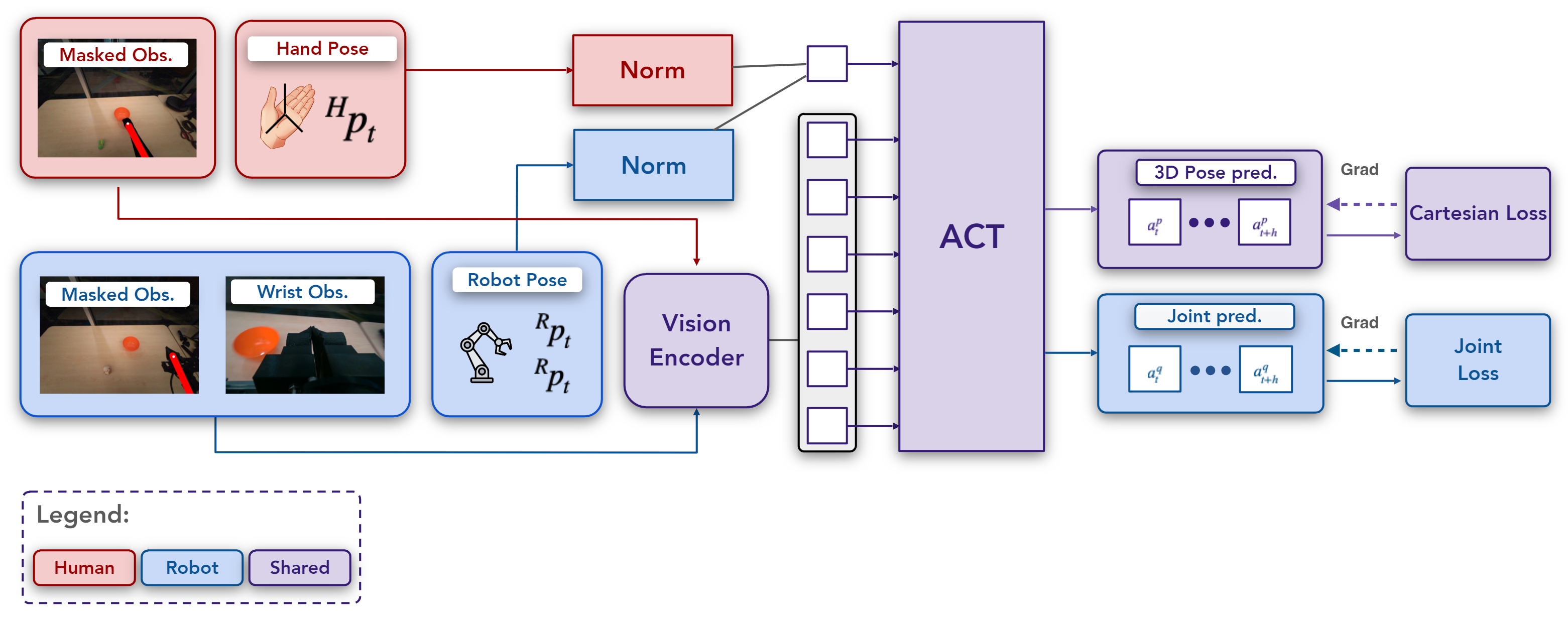
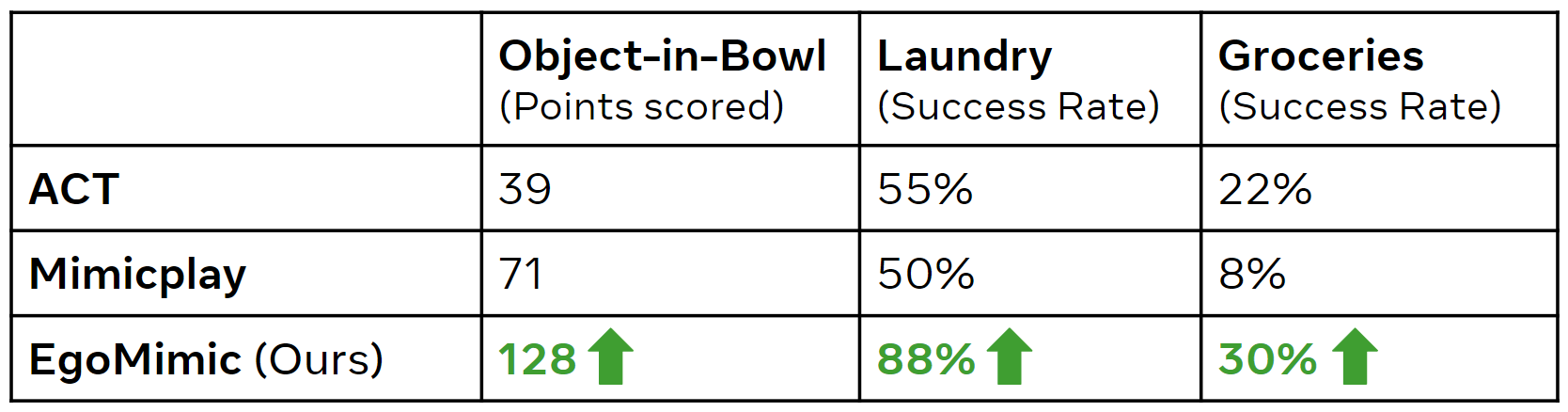
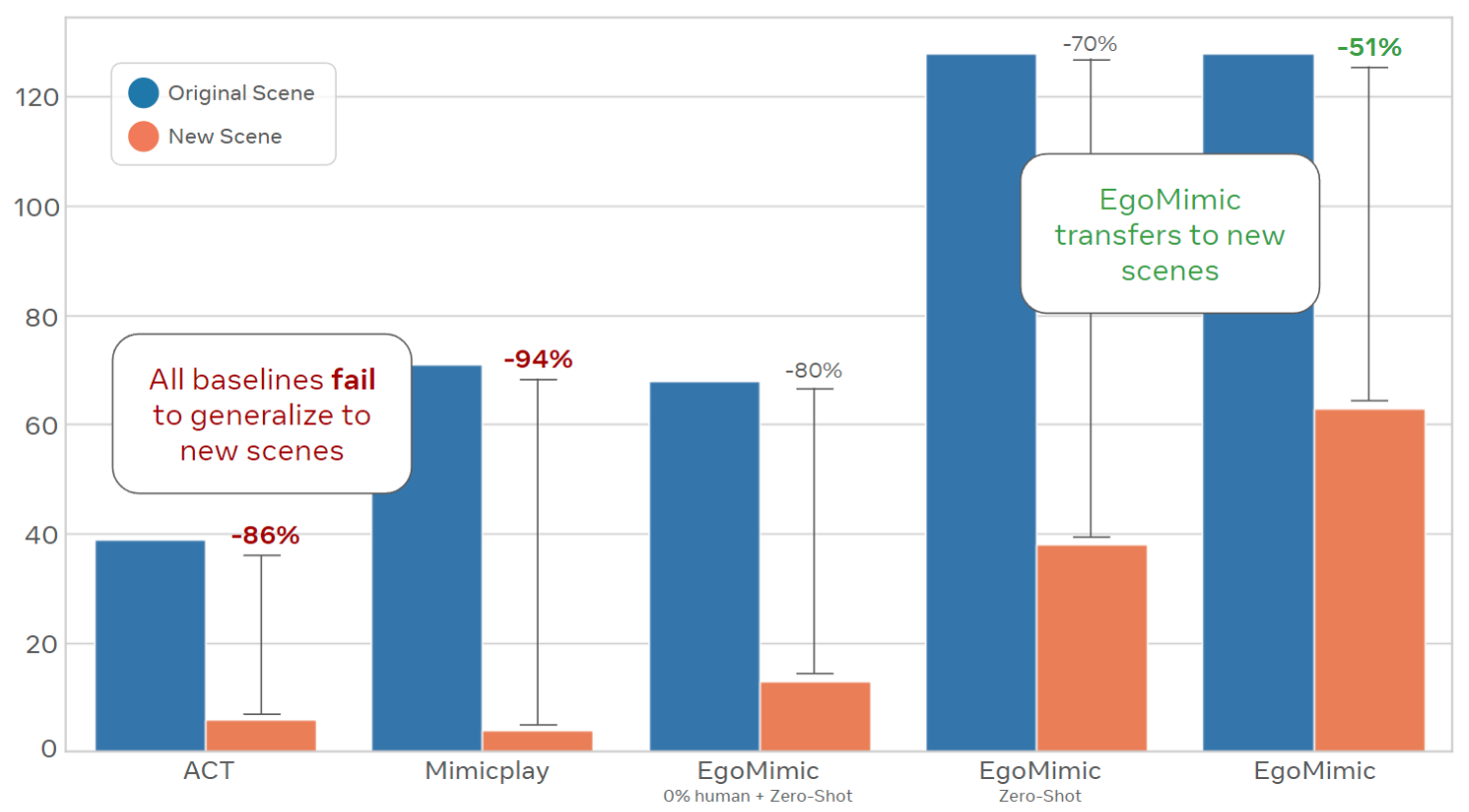
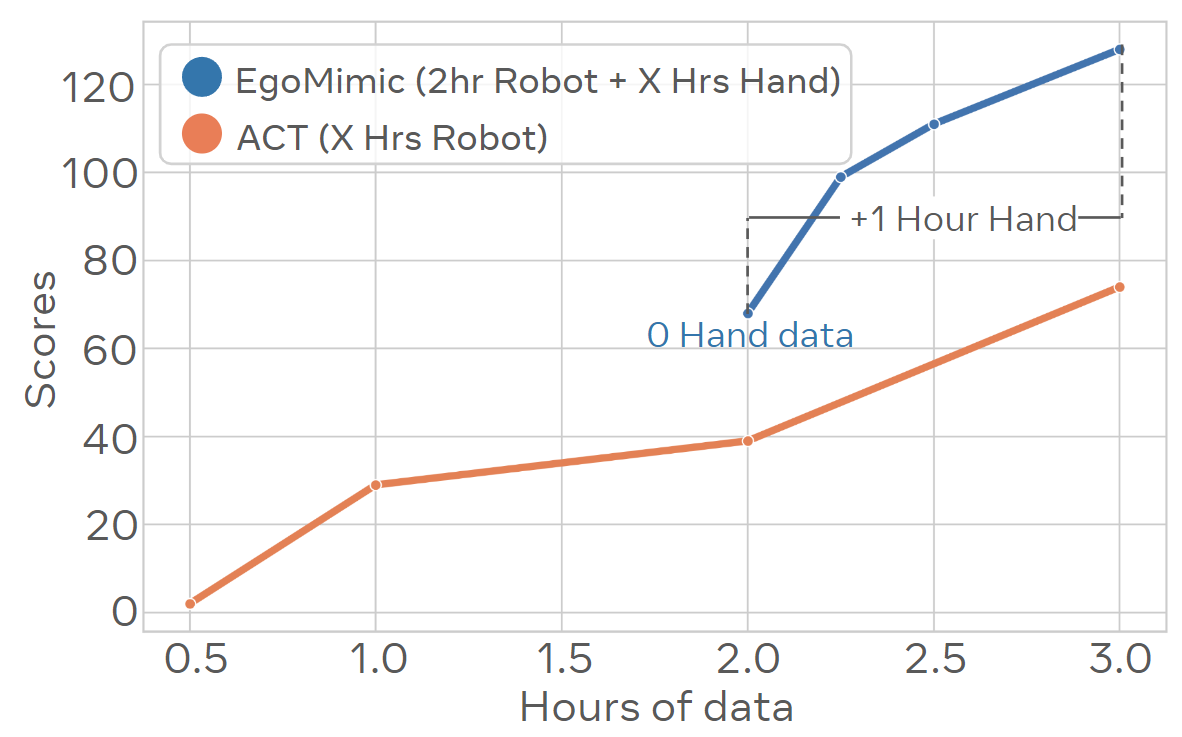
We present EgoMimic, a framework to co-train manipulation policies from human egocentric videos and teleoperated robot data. By leveraging Project Aria glasses, a low-cost bimanual robot setup, cross-domain alignment techniques, and a unified policy learning architecture, EgoMimic improves over state-of-the-art baselines on three challenging real-world tasks and shows generalization to new scenes as well as favorable scaling properties. For future work, we plan to explore the possibility of generalizing to new robot embodiments and entirely new behaviors demonstrated only in human data. Overall, we believe our work opens up exciting new venues of research on scaling robot data via passive data collection.